Client
Educational Technology Sector
Duration
4 months
Year
2025
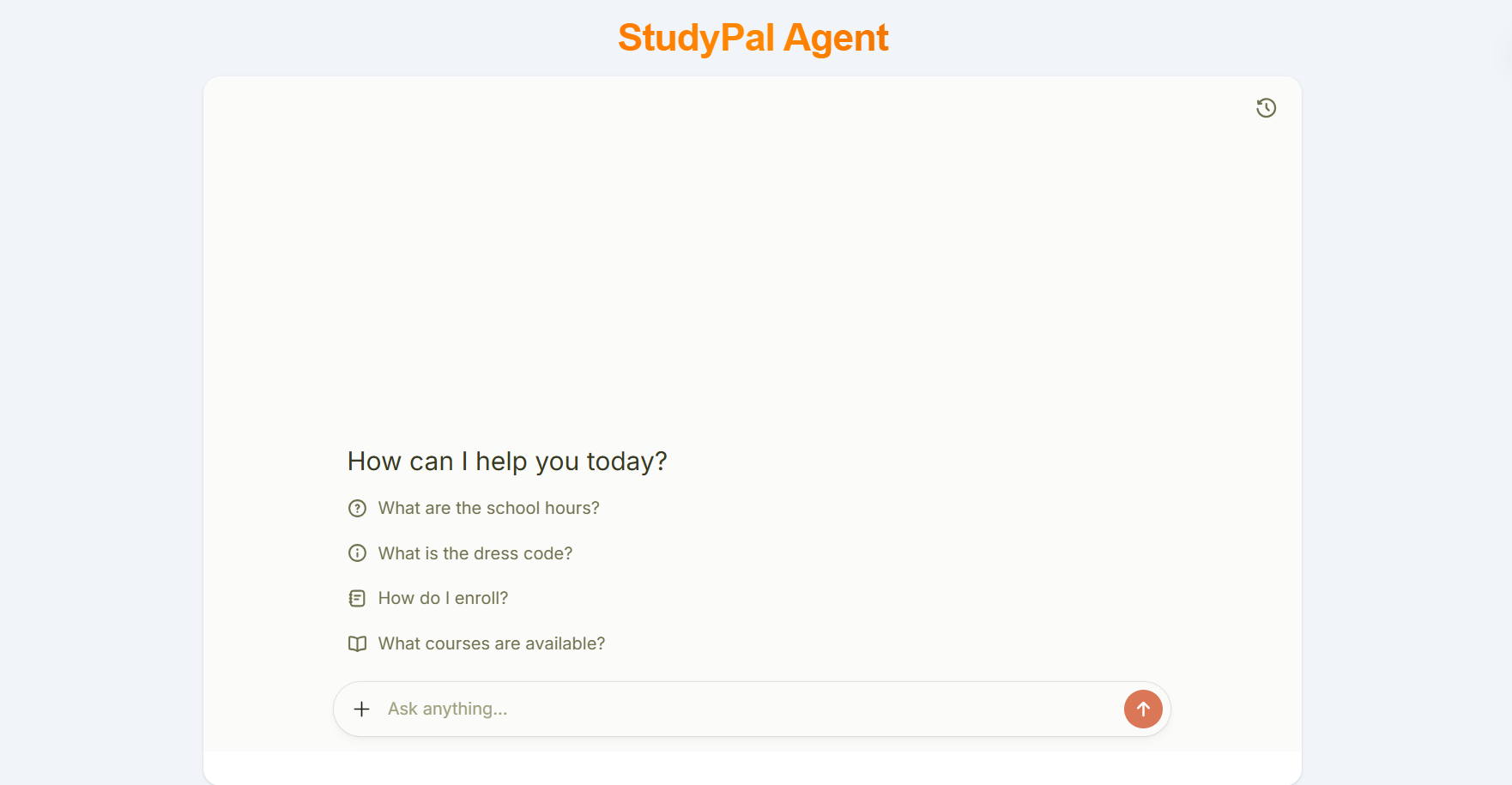
StudyPal Agent is an advanced Retrieval-Augmented Generation (RAG) AI assistant designed to revolutionize how students and professionals interact with educational content. The system processes multiple PDF documents, creates a comprehensive knowledge base, and provides intelligent, context-aware answers to user queries. Powered by ChatGPT's latest language model, StudyPal Agent ensures that responses are drawn exclusively from the uploaded documents, maintaining accuracy and relevance. With user-specific chat history tracking, each user can maintain their own personalized learning journey, review past conversations, and build upon previous interactions. The system combines the power of vector embeddings, semantic search, and large language models to deliver a sophisticated study companion that understands context, maintains conversation history, and provides reliable information for academic and professional research.
Tayyab Shoukat
Developer & AI Enthusiast
Developed a sophisticated RAG-based AI agent using modern AI/ML technologies and vector databases. Implemented a robust PDF processing pipeline that extracts, chunks, and vectorizes content from multiple documents using advanced embedding models. Created a vector database for efficient semantic search and retrieval of relevant document sections. Integrated ChatGPT's latest language model with a carefully designed prompt engineering strategy to ensure responses are grounded in the retrieved context. Built a user authentication and session management system that tracks individual chat histories, allowing users to maintain continuous learning conversations. Designed an intuitive interface where users can upload PDFs, ask questions in natural language, and receive accurate, contextual answers with source references. Implemented conversation memory to enable follow-up questions and contextual understanding across multiple interactions.
Multiple PDFs
Document Processing
Simultaneous PDF analysis capability
95%+
Response Accuracy
Answers grounded in source documents
100%
User Sessions
Personalized chat history tracking
<3 sec
Query Speed
Average response time
The Challenge
Students and researchers often struggle with efficiently extracting information from large volumes of PDF documents. Traditional search methods are ineffective for understanding context and providing comprehensive answers from multiple sources. Users needed an intelligent system that could understand their questions in natural language, search across multiple documents simultaneously, provide accurate answers based solely on the content of those documents, and maintain conversation history for follow-up questions. The challenge was to build a RAG-based system that could handle PDF processing, create searchable vector embeddings, integrate with advanced language models, implement user-based session management, and ensure responses remained grounded in the source material without hallucination.
Developed a sophisticated RAG-based AI agent using modern AI/ML technologies and vector databases. Implemented a robust PDF processing pipeline that extracts, chunks, and vectorizes content from multiple documents using advanced embedding models. Created a vector database for efficient semantic search and retrieval of relevant document sections. Integrated ChatGPT's latest language model with a carefully designed prompt engineering strategy to ensure responses are grounded in the retrieved context. Built a user authentication and session management system that tracks individual chat histories, allowing users to maintain continuous learning conversations. Designed an intuitive interface where users can upload PDFs, ask questions in natural language, and receive accurate, contextual answers with source references. Implemented conversation memory to enable follow-up questions and contextual understanding across multiple interactions.



Our Solution
Developed a sophisticated RAG-based AI agent using modern AI/ML technologies and vector databases. Implemented a robust PDF processing pipeline that extracts, chunks, and vectorizes content from multiple documents using advanced embedding models. Created a vector database for efficient semantic search and retrieval of relevant document sections. Integrated ChatGPT's latest language model with a carefully designed prompt engineering strategy to ensure responses are grounded in the retrieved context. Built a user authentication and session management system that tracks individual chat histories, allowing users to maintain continuous learning conversations. Designed an intuitive interface where users can upload PDFs, ask questions in natural language, and receive accurate, contextual answers with source references. Implemented conversation memory to enable follow-up questions and contextual understanding across multiple interactions.
Students and researchers often struggle with efficiently extracting information from large volumes of PDF documents. Traditional search methods are ineffective for understanding context and providing comprehensive answers from multiple sources. Users needed an intelligent system that could understand their questions in natural language, search across multiple documents simultaneously, provide accurate answers based solely on the content of those documents, and maintain conversation history for follow-up questions. The challenge was to build a RAG-based system that could handle PDF processing, create searchable vector embeddings, integrate with advanced language models, implement user-based session management, and ensure responses remained grounded in the source material without hallucination.

Latest projects
More projects
Let's work together
Ready to bring your vision to life? Get in touch and let's create something amazing together.